Memento Tracer: High Quality Web Archiving at Scale
Memento Tracer is a result of the Scholarly Orphans project funded by Andrew W. Mellon Foundation. The project is a collaboration between the Prototyping Team of the Research Library of the Los Alamos National Laboratory and the Web Science and Digital Library Research Group of Old Dominion University. The Memento Tracer team is: Lyudmila Balakireva, Martin Klein, Harihar Shankar, Herbert Van de Sompel.
What - The Memento Tracer Framework
The Memento Tracer framework introduces a new collaborative approach
to capture web publications for archival purposes. It is
inspired by existing capture approaches yet aims for a new balance
between the scale at which capturing can be conducted and the quality of the snapshots that result.
Like existing web crawler approaches,
Memento Tracer uses server-side processes to capture web publications.
As is the case with LOCKSS, these processes leverage
the insight that web publications in any given portal are typically based on the same template
and hence share features such as lay-out and interactive affordances.
As is the case with webrecorder.io,
human guidance helps to achieve high quality captures. But with Memento Tracer, heuristics that apply
to an entire class of web publications are recorded, not individual web publications. These heuristics can collaboratively
be created by curators and deposited in a shared community repository.
When the server-side capture processes come across a web publication of a class for which heuristics are
available, they can apply them and hence capture faithfull snapshots at scale.
Why - Scale and Quality in Web Archiving
In order to archive the essence of a web publication, a range of web resources need to be captured. But, many times,
capturing those resources is not trivial.
The crawling approaches used by web archives such as the Internet Archive
are optimized for scale and, especially when pages contain advanced interactive features,
fail to assemble a faithfull snapshot of the publication. Also, since on-demand archiving services, like
Save Page Now, offered by these
archives use the same crawling approach, these manually nominated snapshots frequently also lack in quality.
webrecorder.io has pioneered a groundbreaking approach to archive
snapshots of web publications. It is a personal web archiving tool in which all resources
that a user navigates during a session are collected. As such, it also allows generating a high quality
snapshot of what the user regards to be the essence of a web publication. Since the manual navigation process
needs to be repeated for each web publication, the approach is not used to populate web archives at scale.
The LOCKSS archiving framework focuses on capturing scholarly articles
published on the web. These articles reside in a variety of publisher portals, each of which uses a different
user interface. However, within the confines of a publisher portal or
scholarly journal, the interface typically remains the same. As such, the LOCKSS web crawler is equipped
with portal-specific or journal-specific heuristics that support collecting high quality snapshots
of scholarly web publications. These heuristic are expressed in code and are not usable beyond the LOCKSS
framework.
Experimental work at Old Dominion University aimed at discovering URLs accessible from a web resource
beyond those that could be found through regular web crawler approaches. To that end, once a resource had
been obtained, JavaScript functions from a
select set of popular libraries were extracted and exhaustively executed by a headless browser. The approach
effectively yielded a substantial increase in
discovered URLs. But, among others, because the extraction and execution had to be repeated for every page,
the approach turned out to be significantly slower than regular web crawling, and hence
not feasible for operation at scale. Also, because of the nature of the extraction approach,
many URLs accessible from the web resource via manual interaction remained undiscoverable.
Memento Tracer is inspired by all these approaches but aims to strike a new balance between the
scale of capturing and the quality of resulting captures.
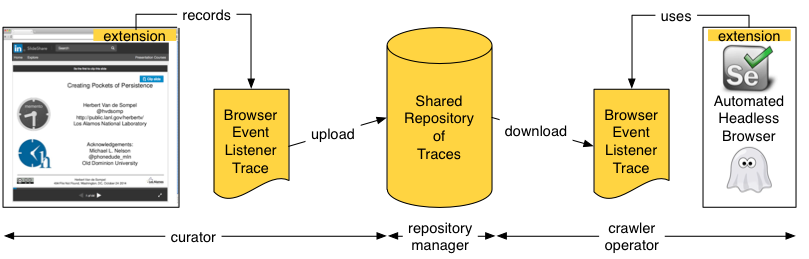
How - The Three Components of Memento Tracer
The Memento Tracer frameworks consists of:
- A component, e.g., a browser extension that records Traces; a Trace is a set of instructions for capturing the essence of web publications of a certain class.
- A component, e.g., a shared repository where the community uploads and downloads Traces.
- A component, e.g., a headless browser extension that uses Traces as guidance in the process that navigates and captures web publications.
Step 1 - A Curator Records a Trace Using a Browser Extension
A curator who anticipates the need to collect a significant amount of web publications from a certain portal over time,
navigates towards a publication that is representative for a class of publications in that portal. For example, if there
is a need to web archive slideshare presentations, the curator might navigate towards the landing page for the
Creating Pockets of Persistence
presentation. On that page, the curator activates the Memento Tracer browser extension to start recording a Trace for
the page by interacting with it. The extension does not record the actual resources or URLs that are traversed by the curator.
Rather, the extension's browser event listener captures mouse actions and records those abstractly in terms that
uniquely identify the page's elements that are being interacted with, e.g. by means of their
class ID or XPath. Since all pages of
the same class are based on the same template, the resulting Traces apply across all pages of the class rather than to this specific page only.
Currently, in addition to recording simple mouse-clicks, the extension is able to record - with a single interaction by the curator -
the notion of repeated clicks (e.g., navigate
through all slides of the presentation) and clicks on all links in a certain user interface component.
For example, below is a Trace that results from the curator indicating that the "next slide" button should be clicked repeatedly.
Note that the Trace also indicates the URL pattern to which the Trace applies,
and provenance information including the resource on which the Trace was created and the user agent used to create it.
When the lay-out and/or affordances for a particular class of web publications changes, a new Trace has to be recorded to
ensure that captures maintain their high quality.
{
"portal_url_match": "(slideshare.net)\/([^\/]+)\/([^\/]+)",
"actions": [{
"action_order": "1",
"value": "div.j-next-btn.arrow-right",
"type": "CSSSelector",
"action": "repeated_click",
"repeat_until": {
"condition": "changes",
"type": "resource_url"
}
},
{
"action_order": "2",
"value": "div.notranslate.transcript.add-padding-right.j-transcript a",
"type": "CSSSelector",
"action": "click"
}
],
"resource_url": "https://www.slideshare.net/hvdsomp/creating-pockets-of-persistence",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/68.0.3417.0 Safari/537.36"
}
Step 2 - A Curator Uploads the Trace to a Shared Repository
Once a Trace is successfully recorded, the curator uploads it into a shared community repository. This can, for example, be done
by means of a pull request to a GitHub repository, which is subsequently evaluated by the maintainers of the repository.
The organization of the repository allows to quickly locate Traces for specific classes of pages and by specific curators.
Since the perspective of what the essence of a web publication is may differ from one curator to the next, the repository
supports multiple Traces for a specific class of pages. Each can be unambiguously identified in the repository.
Also, since the layout of pages evolves over time, Traces will need
updating. This makes version support by the repository essential.
Step 3 - An Operator of a Headless Browser Set-Up Uses Traces from the Shared Repository
In order to generate captures of web publications, the Memento Tracer framework assumes a set-up consisting of
a web-driver (e.g., Selenium) that allows automating the actions of
a headless browser (e.g., PhantomJS) combined
with a capturing tool (e.g., WarcProxy)
that writes resources navigated by the headless browser to a WARC file.
An operator of this set-up selects Traces for those classes of pages that are frequently
crawled and for which high quality snapshots are required. From then onwards, when the fully automated set-up
happens upon a web publication that resorts under a class of pages for which a Trace is available (e.g. its URL resembles the
URL of the web publication for which the Trace was recorded), that Trace will be invoked to guide the capturing process.
When - Current Status
It is hard to say when Memento Tracer will be ready for a test ride, let alone for prime time.
The components are currently experimental but we are making promising progress.
The process of recording Traces and capturing web publications on the basis of these Traces
has been demonstrated successfully for publications in a range of portals. But there also remain challenges
that we are investigating, including:
- User interface to support recording Traces for complex sequences of interactions.
- Limitations of the browser event listener approach for recording Traces.
- Language used to express Traces.
- Organization of the shared repository for Traces.
- Selection of a Trace for capturing a web publication in cases where different page layouts and interactive affordances are available for web publications that share a URI pattern.
Last update: May 10 2018